


Website scraping can help businesses find out more about their competitors, do research, and get information about their own companies.
However, it often comes with frustrating Web Scraping Challenges. Scrapers can’t automatically get data because of CAPTCHAs, IP bans, and other blocking techniques. This post talks about the most common problems with web scraping and how to solve them.
What are the biggest problems with web scraping?
The main obstacles in web scraping include CAPTCHAs, IP blocking, geo-restrictions, real-time data challenges, login requirements, and more. Additionally, websites dynamically load content using JavaScript or AJAX, which traditional scrapers can’t handle. Browser fingerprinting, user-agent verification, honeypot traps, rate restrictions, and structural changes also complicate scraping.
The key lies in using reliable proxy rotation strategies and choosing the right scraping tools that support session handling, headless browsing, and adaptive request behavior.
In the next section, we’ll dive deeper into how proper proxy management and well-chosen software solutions help overcome even the toughest scraping barriers!
Understanding these web scraping challenges from both offensive and defensive perspectives is crucial — knowing how websites protect themselves can inform more effective scraping strategies, and vice versa. For a deeper look into anti-scraping techniques, see this guide on preventing website scraping.
Scalability issues, pagination difficulties, incomplete or inconsistent data, and slow-loading websites due to heavy scripts or media are further challenges. Effective scraping requires robust error handling, data cleaning, and infrastructure planning to maintain efficiency and data integrity.
Let’s solve all these challenges quickly and easily
1. Dynamic Content: A Core Web Scraping Challenge
Many modern websites utilize technologies like JavaScript and AJAX to load content dynamically after the initial page load. Traditional scrapers that only parse static HTML may miss this content. Websites are frequently updated, which can break existing scraper code that relies on specific HTML elements or CSS selectors. Regular monitoring and maintenance are crucial to adapt to these changes.
Solutions
- Headless Browsers: These are web browsers that don’t have a graphical user interface (GUI). Like a standard browser, they can render HTML, CSS, and JavaScript, which lets you see material that loads dynamically. Some of the most popular headless browser tools are:
- Selenium is a strong framework for automating browsers that is often used for testing web apps and dynamic web scraping. Selenium lets you operate a web browser programmatically and interact with pages that use JavaScript like a real person would.
- Puppeteer is a Node.js library that lets you control Chrome or Chromium over the DevTools Protocol using a high-level API. It can be used to automate things like starting a browser, going to pages, clicking buttons, filling out forms, and getting data.
Learn how headless browsers like Puppeteer or Selenium can help bypass modern protections and fetch full page data. Check out the full guide: Headless Browser for Web Scraping.
- API Scraping: A lot of dynamic websites use APIs (Application Programming Interfaces) to get data. You can find these API endpoints by looking at the network tab in your browser’s developer tools. Then you can send requests directly to them to get the data. PromptCloud says that copying these calls into your scraping programs makes sure you get the dynamically loaded data right.
- JavaScript Execution: PromptCloud says that instead of having the browser run JavaScript, you may utilize tools like Puppeteer and Playwright to run JavaScript directly in your scraping scripts. This lets you get content that these scripts made.
When you come across dynamic content, you need to use methods that mimic the activities of a browser to make sure that the JavaScript runs and the material is displayed before you try to interpret it. When it comes to online scraping, headless browsers and API scraping are two of the best ways to deal with dynamic content.
2. How to Get Around CAPTCHAs When Scraping
Behavior-based protection like Cloudflare or Distil JavaScript challenges, cookie checks, honeypot traps, and CAPTCHAs are common on modern websites. These are typical web scraping challenges that block automated tools. Standard HTTP clients without JavaScript cannot pass such checks.
CAPTCHAs tell the difference between people and bots. A lot of websites turn them on when they see strange behavior, such as requests that come in quickly or patterns that don’t make sense. Knowing how to bypass CAPTCHA when scraping is essential to avoid interruptions and maintain smooth data extraction.
When scraping, you can skip CAPTCHAs:
- Puppeteer and Selenium are two headless browsers that can act like people.
- Services that solve CAPTCHAs using image recognition or people should be added.
- To avoid being caught, lower the number and pattern of your requests.
There are different types of CAPTCHAs. Google reCAPTCHA v3 keeps track of how visitors act and is harder to get around with simple ways.
To prevent suspicion, think about delaying interactions, scrolling the page, or adding mouse movement scripts to make it look like you’re really browsing.
3. IP Blocks: How to Avoid Bans and Web Scraping Obstacles
Websites often ban IP addresses when they detect unusual or automated activity. Here’s why this happens:
- High request frequency: If you send too many requests from the same IP in a short time, it looks suspicious.
- Uniform request patterns: Repeated, identical requests or errors from one IP are easy for anti-bot systems to spot.
- Known proxy or VPN IPs: If your IP is already on public proxy/VPN blacklists, you’ll get blocked quickly.
- Geographic anomalies: Requests from unexpected countries or regions can trigger bans.
- Technical fingerprints: Non-standard browser fingerprints or DNS leaks can reveal automation.
How to Easily Avoid IP Bans
- Use a proxy pool: Rotate your requests through a large set of proxies, so no single IP gets overloaded.
- Distribute requests: Spread your traffic across different IPs and geographic locations to mimic real users.
- Randomize behavior: Add random delays, vary request headers (User-Agent, Referer), and avoid sending requests in a strict rhythm.
- Monitor proxy health: Automatically remove proxies that get frequent errors or bans from your pool.
- Emulate browsers: Use headless browsers or tools that mimic real browser fingerprints to avoid detection.
- Limit concurrency: Don’t send too many parallel requests from the same IP—keep it to a reasonable number (like 5–10).
By following these simple strategies, you can significantly reduce the risk of getting your IP banned while web scraping.
4. Honeypot Traps: Hidden Web Scraping Challenges
Honeypot traps help websites detect and stop bots. It adds HTML fields or links that human users cannot see but automated scripts may identify and interact with.
- Hidden form fields: CSS-styled input fields (display:none or visibility:hidden) that are not visible to humans. A bot filling up and submitting these fields alerts the site to its fake identity.
- Invisible links or buttons: Bots who click everything may trigger these traps without genuine users interacting.
- Fake navigation paths: Some sites include links to dead ends or error pages only bots can follow.
Tips to Avoid Honeypot Traps
- Parse and respect CSS/JS: Your scraper should ignore CSS/JS-hidden elements.
- Avoid filling every field: Skip hidden or suspiciously titled form fields like “email_confirm_hidden” and fill out visible ones.
- Copy real user behavior: Be a real user and don’t click every link or button or submit forms with extra info.
- Use browsers without heads: Using Selenium or Puppeteer to render pages like real browsers helps prevent hidden traps.
- ensure the DOM: Before submitting forms, ensure which fields are visible and required.
- Be random: Fill forms in different orders and navigate differently.
Be careful and make your bot act like a human to avoid honeypot traps and getting detected and blocked.
5. Rate Limiting: A Common Challenge in Web Scraping
Restricting the number of requests a single user can make within a given period to prevent server overload. Implementing delays between requests, randomizing request intervals, and rotating IP addresses can help bypass rate limits.
Websites and APIs use rate limiting to limit the number of queries a user or IP address can make in a certain amount of time. If you go beyond this limit, you might get:
- Errors with HTTP 429 that say “Too Many Requests”
- IP blocks that last a short time or forever
- Longer wait times or CAPTCHAs
Why is this a problem?
- Stops automation: Scrapers and bots can easily hit these restrictions, which might lead to interruptions or bans.
- Makes things less efficient: You can’t get data as rapidly as you’d like.
- Triggers anti-bot systems: If you hit the limit too many times, your activity may be flagged as suspicious.
How to Get Around Rate Limiting
- Proxy rotation: Spread requests out among a group of proxies so that no one IP goes over the limit.
- Randomized delays: Put random pauses between queries to make it look like a person is surfing and to avoid patterns.
- Follow the site’s rules: If you can, stay just below the known rate limit so you don’t get caught.
- Multiple sessions at the same time: To speed things up, use more than one account or session, each with its own proxy.
- Keep an eye on responses: If you encounter HTTP 429 or a similar error, stop what you’re doing.
- Adaptive throttling: Change the rate of your requests based on how the server responds and how many errors there are.
You may lessen the effects of rate restriction and keep your scraping or automation going smoothly by using these tactics together.
Tip: Pay attention to changes. Use delta scraping or ETag headers to cut down on the amount of data you have to send.
6. Browser Fingerprinting: Avoiding Advanced Web Scraping Obstacles
By looking at browsers and devices, websites can monitor humans and bots. Characteristics include:
UAC string, screen resolution, color depth, fonts, add-ons, Timezone, language, Canvas/WebGL rendering, HTTP header order, TLS/SSL handshake data (JA3 fingerprint), and enabled features (cookies, JavaScript).
Your browser fingerprint can disclose your identity or automation even if you change your IP address or utilize incognito mode.
What’s wrong?
- Bot detection: Anti-bot solutions block automation via fingerprinting.
- Even with various IPs, sites may monitor visitors between sessions.
- Many fingerprint qualities are faint, making them difficult to capture.
Easy Way to Stop Browser Fingerprinting
- Headless browsers with stealth plugins: Puppeteer and Playwright can mimic actual browsers and hide automation.
- Always make new fingerprints: Change User-Agent strings, screen widths, and other characteristics per session or request.
- Function as browsers: Selenium with undetected-chromedriver or Curl Impersonate matches popular browser fingerprints.
- Resize windows, headers, and other settings: Avoid automation tool defaults.
- Some solutions allow you to fake or disable WebGL, canvas, or plugins to prevent unique signatures.
- Check your fingerprints: Check amiunique.org or browserleaks.com to see how unique your configuration is and make changes.
Avoiding clear automation trends and making your bot’s fingerprint look like a real, diverse mix of browsers will drastically reduce the risk of browser fingerprinting.
7. User-Agent Verification: Minor Detail, Major Scraping Challenge
Websites may reject requests from unknown or suspicious user agents. Spoofing user agents with legitimate browser strings or using browser automation tools like Selenium and Puppeteer can help.
How to Bypass User-Agent Verification
- Rotate User-Agents: Use a pool of up-to-date, popular User-Agent strings (e.g., latest Chrome, Firefox, Safari) and switch them regularly.
- Match other headers: Make sure your other HTTP headers (Accept, Accept-Language, etc.) are consistent with your chosen User-Agent.
- Emulate real devices: Use User-Agents from real devices and browsers, not just desktop but also mobile.
- Avoid rare or outdated User-Agents: Stick to User-Agents that are common and current.
- Randomize per session: Assign a different User-Agent to each session or thread to avoid patterns.
8. Geo-Restrictions: Getting Past Regional Web Scraping Challenges
Some content is only available in certain areas. If your IP address isn’t local, your scraper can be blocked.
To get around geo-restrictions:
- Use proxies that are particular to your country.
- Choose rotating proxies that only work in certain places.
Your IP address tells you where you are. Changing your proxy lets you access content that is only available in certain areas without notification.
9. Login Walls: How to Scrape Authenticated Content
In some cases, you’ll need to provide credentials to access a website’s content. This is problematic for web scraping because the scraper must simulate the login process and provide the credentials to gain access to the data. You can learn more about how to scrape a website that requires a login in our complete guide.
After receiving the login information and granting access, the target website may use cookies or tokens to keep your scraper authenticated throughout its time there. That means your scraper needs to be able to store and send the appropriate cookies or tokens to keep the authenticated state active.
Ways to deal with:
- Use a scraper that handles sessions.
- Cookie management that is programmed keeps track of login status.
- For headless browser logins, keep session tokens.
- A lot of sites utilize CSRF tokens and other tests to log in. Follow the login flow exactly.
Don’t log in from the same IP address too often. This could make people suspicious or need more protection.
10. Handling Pagination and Navigation in Complex Scraping Scenarios
Navigating websites with complex pagination or infinite scrolling can be challenging for automated scrapers. Solutions include automated pagination handling and simulating scrolling actions.
How to Handle Pagination and Navigation in Web Scraping
1. Analyze the Site’s Structure
- Inspect how pagination works: Is it via URL parameters (e.g., `?page=2`), “Load More” buttons, or infinite scroll?
- Check if navigation requires JavaScript execution.
2. Automate URL-based Pagination
- If pages are numbered in the URL, generate the URLs programmatically and scrape each one.
- Example: `example.com/products?page=1`, `page=2`, etc.
3. Handle “Load More” and Infinite Scroll
- Use headless browsers (like Selenium, Puppeteer, or Playwright) to simulate clicking “Load More” or scrolling down.
- Wait for new content to load before extracting data.
4. Manage Navigation Links
- Parse the HTML to find “Next” or page number links.
- Follow these links recursively or in a loop until you reach the last page.
11. Scalability and Performance
Scaling web scraping operations to handle large volumes of data and multiple websites requires careful planning and infrastructure maintenance. Cloud-based platforms, distributed scraping strategies, and efficient resource management can be beneficial. Addressing scalability early helps prevent performance bottlenecks and reduces common web scraping obstacles that arise when handling high loads.
Key Points
- Microservice Architecture: The scraping system utilizes different services: scheduler, parser, proxy manager, data store, and API gateway. This lets each part scale independently.
- Containerized and orchestrated, managing several parallel scraping operations with Docker and Kubernetes. With system load, Kubernetes can automatically increase or reduce worker count.
- Distribute tasks evenly across the system using message queues such as Redis Queue, RabbitMQ, AWS SQS, or Kafka.
- Proxy Balancing and Rotation: Algorithms (random, round-robin, weighted) distribute requests equally to prevent IP overload.
- Monitoring and notifications: The system tracks metrics (latency, success, ban) and triggers automatic notifications for prompt issue resolution.
- Fault Tolerance: Automatically switch to backup proxies or lower load during failures, preventing downtime.
- Optimize Parallelism: Limit concurrent connections, create pauses, and simulate user behavior to avoid proxy overload.
Methods for Scalability and Performance
- Create a distributed, autonomous service architecture.
- Containers and orchestrators enable flexible process management.
- Balance load with task queues.
- Automate proxy rotation and health monitoring.
- Track metrics and create alarms.
- Manage backup proxy pools and failover.
- Keep parallelism and bot behavior updated to fit user habits.
By following these strategies, you can create robust, scalable, and high-performance scraping systems that are resilient to blocks and failures.
12. Data Cleaning and Structuring
Scraped data is often raw, unstructured, and messy, requiring cleaning, parsing, and formatting before it can be used effectively. These issues represent some of the most common Web Scraping Challenges, as inconsistencies in HTML structure, dynamic content loading, and duplicate data can significantly complicate the extraction and analysis process.
Use parsing libraries, validation, and normalization to clean and structure scraped data.
- Parsing libraries: Use tools like BeautifulSoup, lxml, or Cheerio to extract data accurately.
- Validation: Check for missing, duplicate, or malformed entries.
- Normalization: Standardize formats (dates, numbers, text case).
- Deduplication: Remove repeated records.
- Export: Save cleaned data in structured formats like CSV, JSON, or databases.
Tools and Proxies for Bypassing Obstacles
To scrape effectively and without stopping, you need the right tools and abilities. It’s crucial to know how to use Scrapy, BeautifulSoup, and headless browsers like Playwright, but don’t promote any specific services.
Proxy as a Service: Architecture Options
There are different ways to organize a proxy pool. A local pool assigns each thread its own proxy list, but lacks centralized control. A better option is a remote proxy service — a separate app or microservice that stores the entire proxy pool and provides proxies via API. For instance, proxies can be stored in Redis, and accessed through a FastAPI or Go-based service. Each thread sends a request like “Give me a working proxy,” and the service returns one based on availability and performance. It can also track stats like uptime, error rate, and CAPTCHA frequency, simplifying health monitoring and state synchronization.
Ready-to-use solutions include Python libraries like proxybroker (for gathering and filtering public proxies), scrapy-rotating-proxies, and others. Commercial tools like Zyte Smart Proxy Manager or Bright Data Proxy Manager offer advanced routing logic — e.g., Bright Data’s “Waterfall Routing” tries a mobile proxy first, then residential, then datacenter, improving success rates and reducing errors.
Proxy Health Monitoring:
- Regularly test proxies with sample requests.
- Track stats: error count, CAPTCHA frequency, success rate.
- Remove proxies that repeatedly fail or trigger CAPTCHAs (quarantine them).
This helps automatically eliminate bad or blocked proxies and saves resources.
Rotation Proxy Strategies
The main idea behind proxy rotation in web scraping is dynamic IP address obfuscation to mimic natural user behavior and bypass website restrictions. This technique helps reduce detection and mitigate Web scraping challenges such as IP bans, rate limiting, and access denial due to geographic or behavioral filters.
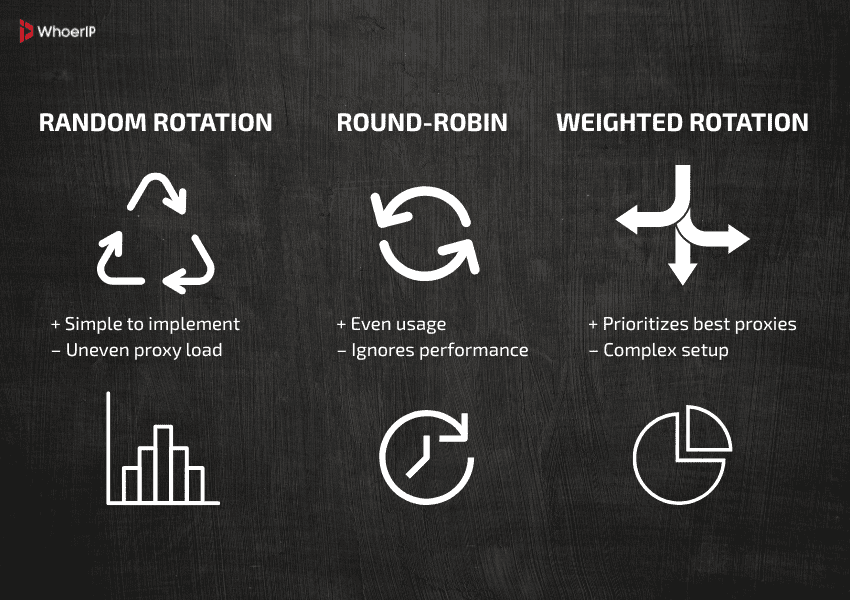
Proxy rotation strategies can vary:
- Random: Assign proxies at random — simple, but may lead to uneven load.
- Round-robin: Cycle through proxies in order — ensures balanced usage.
- Weighted: Assign weights based on proxy performance — faster, more reliable proxies are used more often. Weights can adjust dynamically using metrics like latency, success rate, or ban frequency.
When is a proxy considered “dead” or “unusable”?
A proxy is considered “dead” if it triggers frequent timeouts, HTTP 5xx or 403/429 errors, or repeated CAPTCHAs. The system can downgrade its score or remove it temporarily based on failure thresholds or performance degradation.
Useful Metrics for Proxies and Parsing
Proxies can become slow, unreliable, or even get blocked by websites. By monitoring metrics like proxy speed, reliability, uptime, and error rates (e.g., number of failed requests), you can identify problematic proxies and rotate them out of your pool.
- Latency (Response Time):
Track median and percentile response times. Rising latency may indicate overloaded proxies or target servers. - Request Rate (TPS):
Requests per second processed by the system. Monitoring trends—both drops and spikes—is crucial. - Success/Failure Rate:
The percentage of successful vs. failed requests helps assess system stability. - Ban Rate / Captcha Rate:
The share of requests resulting in bans or CAPTCHAs. A sudden spike should trigger alerts and prompt investigation. - Consecutive Errors:
Number of back-to-back failures (e.g., timeouts, 502s). This often signals a faulty proxy. - Traffic Volume:
Total data transferred. Important when working with proxies billed by bandwidth or when tracking throughput.
Open-Source and Ready-Made Solutions
There are many open-source libraries and tools that can greatly simplify proxy management and scaling web scraping. Here’s a comparison table of open-source and paid proxy managers mentioned in the article.
| Name | Type | Language/Platform | Key Features | Pros | Cons |
| ProxyBroker | Open-source | Python | Finds, checks, rotates free proxies; local proxy server | Free, flexible, easy integration | Free proxies unreliable, less support |
| proxy_pool, scrapperpool | Open-source | Python | Local proxy pool, auto-rotation, health checks | Free, customizable | Needs setup, basic UI |
| scrapy-rotating-proxies | Open-source | Python (Scrapy) | Rotates proxies for Scrapy spiders | Simple Scrapy integration | Scrapy-only, basic features |
| GoProxy | Open-source | Go | HTTP proxy server, loads proxy lists | Fast, lightweight | Minimal features |
| browserless, puppeteer-cluster | Open-source | Node.js | Headless browser proxy pool, parallel tasks | Great for browser scraping | Resource-intensive |
| Zyte Smart Proxy Manager | Paid | API/Cloud | Smart routing, waterfall fallback, anti-bot features | Reliable, advanced anti-bot, support | Paid, usage-based pricing |
| Bright Data Proxy Manager | Paid | API/Cloud | Multiple proxy types, rules, analytics, large IP pool | Huge IP pool, advanced features | Expensive, complex setup |
| Luminati, SmartProxy | Paid | API/Cloud | Residential, datacenter, mobile proxies, API integration | Many locations, high reliability | Paid, can be costly |
Many open-source libraries and technologies facilitate proxy administration and web scraping scaling:
Your goals and budget determine whether to choose open source or commercial solutions. Tools like ProxyBroker are helpful for rapid proxy tests, but under heavy load and concurrency, building your own controller on trustworthy libraries is typically superior.
Ethical and legal considerations
- Respecting robots.txt: This file provides guidelines for web crawlers, indicating which parts of a website should not be accessed. Ethical scrapers should respect these directives.
- Terms of Service (ToS) violations: Many websites prohibit automated scraping in their terms of service. Violating these terms could lead to legal action or account bans, although legal precedents regarding ToS violations in scraping vary depending on jurisdiction and the nature of the data being scraped.
- Copyright infringement: Scraping copyrighted material (e.g., text, images, videos) without permission may violate copyright laws. Focusing on publicly available data or data falling under fair use guidelines is essential.
- Data privacy laws: Scraping personal data, particularly sensitive information, without consent can violate privacy laws like GDPR and CCPA. Prioritizing privacy, obtaining necessary consent, and anonymizing data are crucial.
- Impact on website resources: Aggressive scraping can overload website servers and disrupt service for other users, potentially even causing denial-of-service (DoS) attacks. Implementing rate limiting, avoiding peak hours, and minimizing the number of requests can mitigate this impact.
Conclusion
Web scraping is like a cat-and-mouse game—you find a way around one obstacle, and another appears. But by staying informed, using the right tools, and scraping ethically, you can keep your data collection smooth and sustainable.
Frequently Asked Questions
What are the disadvantages of web scraping?
Legal issues, blocked access, data inconsistency, and maintenance costs.
Can websites tell if you're scraping?
Yes, through behavior analysis, IP tracking, and fingerprinting.
Why is scraping bad?
It can overload servers, violate terms of service, or misuse data.
What's the difference between web crawling and web scraping?
Crawling discovers URLs; scraping extracts content from those pages.
Can sites block web scraping?
Yes, using CAPTCHAs, firewalls, IP bans, and user-agent checks.
What is the future of web scraping?
Smarter bots, better anti-scraping tech, more legal and ethical scrutiny.
What are the risks of web searching?
Exposure to trackers, unsafe websites, and data collection.
Do hackers use web scraping?
Yes, sometimes to collect public data for phishing or competitive misuse.












